

How Search Engines Find, Process, and Store Your Pages
Crawling and indexing sit at the core of technical SEO. If search engines cannot discover your pages efficiently or decide not to store them in their index, those pages have little chance of performing in organic search, no matter how strong the content may be.
This is where many SEO strategies quietly fail. A website may publish useful content, target the right keywords, and build relevant internal links, yet still struggle because key pages are hard to find, duplicated across multiple URLs, blocked unintentionally, or simply not considered worthy of indexing. In those situations, the issue is not always content quality alone. It is often the relationship between the site’s technical setup and how search engines process it.
That is why understanding crawling and indexing matters. These are not abstract search engine concepts. They directly affect visibility, discoverability, and the efficiency of your broader SEO efforts. This article explains what crawling and indexing are, why they matter, how they work, what commonly goes wrong, and how to approach them strategically.
What Is Crawling and Indexing?
Crawling and indexing are two separate stages in how search engines process websites.
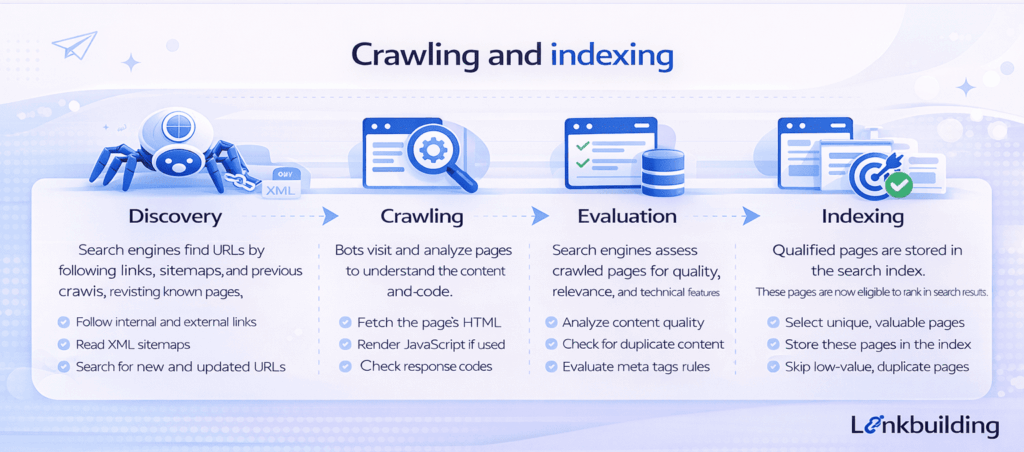
Crawling is the process of discovering and visiting URLs. Search engines use bots to follow links, read sitemaps, revisit known pages, and find new content across the web.
Indexing is the process of storing and organizing selected pages in the search engine’s index after they have been crawled and evaluated. If a page is not indexed, it is unlikely to appear in search results in any meaningful way.
In practical terms, crawling is about access. Indexing is about inclusion.
This distinction matters because a page can be crawled without being indexed. It can also be technically indexable but difficult to crawl because it is poorly linked, buried deep in the site, or blocked by technical obstacles.
When people talk about crawling and indexing in SEO, they are really talking about whether search engines can reach the right pages, understand them clearly, and decide they deserve to be stored and surfaced.
Why Crawling and Indexing Matter
Crawling and indexing matter because they determine whether your site’s important pages can even enter the ranking conversation.
They shape search visibility
Before a page can rank, it has to be discovered, processed, and included in the index. If that sequence breaks down, the page remains invisible regardless of how well written it is.
They influence crawl efficiency
Search engines do not spend unlimited attention on every website. If too much crawl activity is wasted on duplicate URLs, low-value archives, filter combinations, or broken pages, important URLs may be discovered or refreshed less efficiently.
They support index quality
A strong SEO setup is not about getting every possible URL indexed. It is about helping search engines index the right pages. Too many thin, duplicate, or low-priority pages in the index can weaken overall site quality and reduce clarity.
They affect site architecture and topical authority
Crawling and indexing are strongly connected to site structure. When important pages are linked clearly, grouped logically, and supported by clean technical signals, search engines can understand the relationship between topics more effectively.
For a website using a topical cluster strategy, this is especially important. A broader technical SEO guide may link naturally to deeper content on XML sitemaps, canonical tags, internal linking, crawl budget, or index bloat. Crawling and indexing help determine whether those supporting pages are actually discovered and stored properly.
How Crawling and Indexing Work
Search engines move through several stages before a page becomes eligible to rank. Crawling and indexing sit at the center of that process.
Discovery
Everything begins with discovery. Search engines find pages through internal links, backlinks, XML sitemaps, redirects, and historical crawl data.
Pages that are well connected through internal links are usually easier to find. Pages with no meaningful internal access often become orphaned or delayed in discovery.
Crawling
Once a page is discovered, the search engine decides whether to crawl it. That decision may be influenced by the page’s importance, the site’s crawl patterns, server health, response codes, robots directives, and how often the URL changes.
Crawling does not mean a page will be indexed. It simply means the search engine has requested and reviewed the page.
Rendering and evaluation
Many pages are also rendered, especially if they rely on JavaScript. At this stage, search engines try to understand the content, structure, links, and signals on the page.
If important content only appears after unreliable rendering or key links are missing from the accessible HTML path, interpretation can suffer.
Indexing decision
After evaluation, the search engine decides whether the page belongs in the index. This decision is shaped by quality, uniqueness, duplication, canonical signals, relevance, and technical clarity.
Some pages are crawled but not indexed because they are too similar to others, offer limited value, or send conflicting signals about which version should be considered primary.
Important Subtopics Within Crawling and Indexing
Crawlability
Crawlability refers to whether search engines can access a page at all. If a URL is blocked, broken, hidden behind poor internal linking, or buried inside a weak architecture, it may not be crawled effectively.
This is where related topics such as robots.txt, internal linking, and technical site structure become important supporting articles in a cluster.
Indexability
Indexability refers to whether a page is eligible to be included in the index. A page may be crawlable but not indexable because of a noindex directive, canonical choice, duplication issue, or quality concern.
Crawlability and indexability are related, but they are not interchangeable.
Internal linking
Internal linking plays a major role in both crawling and indexing. It helps search engines discover pages, understand site hierarchy, and interpret which pages deserve more attention.
Weak internal linking often leads to slow discovery, lower crawl priority, and weaker contextual signals.
XML sitemaps
XML sitemaps help search engines find important URLs, especially on larger or frequently updated sites. They are not a replacement for good internal linking, but they can support discovery and prioritization.
A good sitemap should include indexable, canonical URLs that actually matter. Bloated sitemaps often reduce their own usefulness.
Canonicalization
Canonical tags help search engines understand which version of similar or duplicate pages should be treated as primary. They are especially important when multiple URLs can serve similar content.
A related article on canonical tags or duplicate content would sit naturally alongside this topic.
Crawl budget and index bloat
Not every site needs to obsess over crawl budget, but large or complex sites often benefit from managing crawl waste carefully. Index bloat, meanwhile, becomes a problem when too many low-value pages enter the index and dilute overall site quality.
These are useful subtopics for deeper supporting content within a technical SEO cluster.
Common Mistakes With Crawling and Indexing
Letting low-value pages enter the index
Search result pages, tag archives, faceted URLs, and thin utility pages often get indexed without a clear SEO purpose. That weakens index quality and can waste crawl resources.
Blocking the wrong pages
Developers or site owners sometimes block content unintentionally through robots directives, noindex usage, or template settings. This can keep important pages out of search entirely.
Relying too heavily on sitemaps
Sitemaps help, but they do not replace good architecture and internal linking. If important pages are only discoverable through a sitemap, the site structure may need work.
Creating duplicate URL paths
Parameter URLs, inconsistent internal linking, pagination patterns, or CMS quirks can create unnecessary duplication. That makes indexing decisions harder for search engines.
Assuming crawled means indexed
A page can be crawled and still not make it into the index. That often happens when the content is weak, duplicative, or technically ambiguous.
Practical Guidance for Better Crawling and Indexing
The best approach to crawling and indexing is strategic, not purely technical.
Start by identifying the pages that matter most. These may be service pages, product pages, category pages, or priority informational content. Then ask three questions:
- Can search engines find these pages easily?
- Are these pages clearly indexable?
- Are they the preferred versions within the site?
That simple framework catches many important issues early.
It is also important to control what should not be indexed. Not every URL deserves a place in the search index. A clear indexation policy helps prevent weak pages from competing with stronger ones.
For content-heavy sites, internal linking should support discovery deliberately. Related pages should connect naturally, especially when they sit within the same topic cluster. A page about crawling and indexing can logically link to related articles on XML sitemaps, canonical tags, robots.txt, internal linking, and technical SEO audits.
Finally, look for patterns instead of isolated page problems. If one article has a canonical issue, the problem may exist across an entire template. Template-level thinking is often more valuable than page-level troubleshooting.
Timing and Expectations
Changes to crawling and indexing can affect SEO at different speeds.
Some fixes, such as unblocking an important page or correcting a bad canonical signal, may have an effect relatively quickly once search engines revisit the site. Other changes, such as improving internal linking across a cluster or cleaning up index bloat, may take longer to influence search visibility.
It is also worth setting realistic expectations. Better crawling and indexing do not guarantee stronger rankings on their own. They remove friction and improve clarity. That allows strong content and relevant pages to compete more effectively, but they do not replace content quality or search intent alignment.
Conclusion
Crawling and indexing are fundamental to SEO because they determine whether your most important pages can be discovered, evaluated, and stored by search engines in the first place.
A website does not gain organic visibility simply by publishing content. It earns visibility when the right pages are accessible, technically clear, well connected, and valuable enough to be indexed. That is why crawling and indexing deserve strategic attention, especially on websites building long-term topical authority.
When handled well, they make the entire SEO system more efficient. They help search engines find what matters, ignore what does not, and understand how your content fits together. That foundation makes every other SEO effort more effective.