

Robots.txt SEO: What It Does, What It Does Not Do, and How to Use It Safely
Robots.txt is one of the most discussed files in technical SEO, and also one of the most misunderstood. It looks simple, but small mistakes in robots.txt can affect how search engines crawl large parts of a website. In some cases, it helps improve crawl efficiency. In others, it creates confusion or blocks important pages unintentionally.
That is why robots.txt SEO matters. The file itself is not a ranking factor in the usual sense, and it will not improve weak pages by itself. Its value comes from control. Used correctly, robots.txt helps guide crawlers away from low-value areas and supports a cleaner technical setup. Used poorly, it can interfere with discovery, crawling, and broader SEO performance.
This article explains robots.txt SEO in practical terms. It covers what robots.txt is, why it matters, how it works, what commonly goes wrong, and how to approach it strategically.
What Is Robots.txt SEO?
Robots.txt SEO is the practice of using the robots.txt file to manage how search engine crawlers access sections of a website.
The robots.txt file lives at the root of a domain and provides crawl instructions to compliant bots. In simple terms, it tells search engines which areas of a site they should or should not crawl.
That distinction matters. Robots.txt controls crawling, not indexing directly.
This is where a lot of confusion begins. A page blocked in robots.txt may still appear in search results if search engines discover the URL through links or other signals. Blocking crawling does not automatically mean removing the page from the index.
So when people talk about robots.txt SEO, the real question is not “How do I hide pages from Google?” The better question is “How do I use crawl control to support the site’s technical SEO without sending the wrong signals?”
Why Robots.txt SEO Matters
Robots.txt SEO matters because crawling is not unlimited, especially on larger or more complex sites. Search engines spend time and resources exploring websites. If that attention is wasted on unimportant areas, valuable pages may be crawled less efficiently.
It helps reduce crawl waste
Many websites generate URLs that are not useful for search. These may include internal search results, filter combinations, session-driven pages, staging paths, or utility folders. If crawlers spend too much time in those areas, important pages may receive less efficient crawl coverage.
Robots.txt can help reduce that waste.
It supports cleaner technical priorities
A technically healthy site sends consistent signals about what matters. Robots.txt can support that by keeping crawlers away from parts of the site that do not contribute to SEO goals.
It helps large sites more than small ones
Smaller websites with simple architecture may see only limited benefit from robots.txt refinement. Larger ecommerce sites, publishers, and websites with faceted navigation usually gain more from careful crawl control.
It fits into the wider technical SEO system
Robots.txt should not be treated as an isolated trick. It works alongside XML sitemaps, canonical tags, internal linking, crawling and indexing strategy, and indexation control. It is one part of a broader technical SEO framework.
How Robots.txt Works
Robots.txt works by giving instructions to crawlers before they request certain URLs.
The file can include rules for specific user agents and can allow or disallow access to different paths. Search engines read these directives and decide whether to crawl matching URLs.
A basic example might block crawlers from low-value internal search paths or temporary directories while allowing normal site content to remain crawlable.
What robots.txt does best is manage crawl behavior at the path level.
What it does not do well is control indexation in a precise way. That is why robots.txt SEO requires nuance. If the goal is to stop a page from being indexed, blocking it in robots.txt is often the wrong tool unless you understand the side effects.
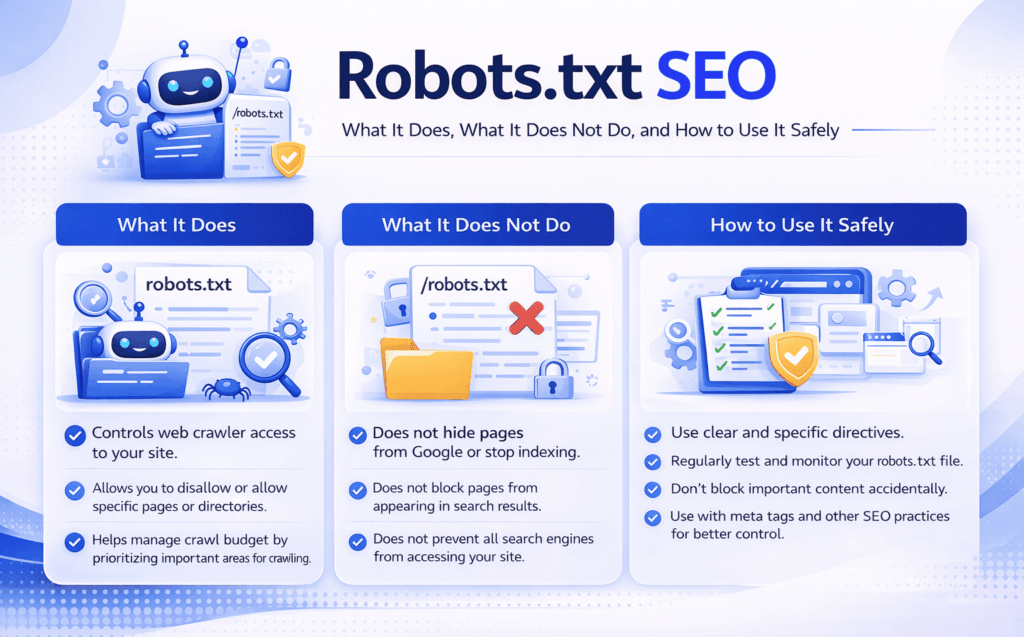
What Robots.txt Does and Does Not Do
Understanding robots.txt SEO becomes much easier once this distinction is clear.
What robots.txt does
Robots.txt can:
- block crawlers from accessing certain paths
- guide compliant bots away from low-value sections
- support crawl efficiency on complex sites
- declare the location of XML sitemaps
What robots.txt does not do reliably
Robots.txt does not:
- guarantee a page will not be indexed
- remove already indexed pages from search
- replace noindex directives
- fix poor internal linking or weak site architecture
- improve rankings by itself
This is why robots.txt should be used carefully. It is a crawl management tool, not a universal visibility control system.
Important Robots.txt SEO Use Cases
Blocking low-value crawl paths
This is the most common and often the most useful application. If a site creates large volumes of filtered, session-based, or utility URLs that do not deserve crawl attention, robots.txt can help keep crawlers focused elsewhere.
Protecting crawl efficiency on large sites
Large sites often struggle more with crawl waste than small sites. Robots.txt can support better crawl behavior when paired with clean internal linking and well-managed XML sitemaps.
Declaring the sitemap location
Many sites include their XML sitemap reference inside robots.txt. This helps search engines discover the sitemap more easily and reinforces the site’s technical structure.
Managing crawler access during technical complexity
Sites with multiple environments, generated paths, or archived sections may use robots.txt to reduce exposure of unimportant crawl areas. That said, robots.txt is not a secure way to protect sensitive content. If something must remain private, other protections are required.
Common Robots.txt SEO Mistakes
Blocking important pages by accident
This is one of the most damaging mistakes. A misplaced disallow rule can stop crawlers from reaching critical content, categories, product pages, or supporting articles.
Even experienced teams make this mistake during migrations, redesigns, or staging launches.
Using robots.txt to control indexation
A page blocked in robots.txt may still be indexed if search engines know the URL exists. If the goal is to prevent indexation, noindex or other appropriate controls are usually more reliable.
Blocking resources needed for rendering
In the past, some websites blocked CSS, JavaScript, or image directories too aggressively. That can make it harder for search engines to understand how pages render and function.
Creating rule conflicts
Overly complex files with too many directives, especially across different bots, can create maintenance problems and increase the chance of errors.
Forgetting to review the file after site changes
Robots.txt often gets edited during launches, migrations, or temporary technical work. Then it gets forgotten. Months later, outdated rules may still be affecting crawl behavior.
Robots.txt SEO and Indexing: A Common Point of Confusion
One of the most important parts of robots.txt SEO is understanding the difference between crawl control and index control.
If a page is disallowed in robots.txt, search engines may not crawl it. But if they discover the URL through internal links, backlinks, or sitemaps, they may still keep a reference to it in the index.
That means robots.txt is not the best choice when the goal is “Do not show this page in search results.”
This topic connects naturally to related cluster articles on crawling and indexing, XML sitemap SEO, and canonical tags. Those topics work together, and treating them separately often leads to technical confusion.
Practical Guidance for Using Robots.txt Correctly
The best approach to robots.txt SEO is disciplined and selective.
Start with a clear question: which parts of the site truly should not consume crawler attention?
On many sites, valid candidates include search result pages, duplicate filter paths, temporary sections, and low-value utility areas. Important commercial pages, priority editorial content, and key category structures should almost never be blocked casually.
It also helps to review robots.txt against the rest of the technical setup:
- Are blocked paths also excluded from XML sitemaps?
- Are important pages still crawlable through internal links?
- Are you trying to solve an indexation problem with a crawl-control tool?
- Do current rules still reflect how the site works today?
On content-driven websites, robots.txt should support the architecture, not fight it. If a site is building topical authority, important cluster pages should be crawlable, internally linked, and technically clear.
Timing and Expectations
Changes to robots.txt can affect crawl behavior relatively quickly once search engines fetch the updated file, but the broader SEO impact depends on the issue being solved.
If the file is currently blocking important content, fixing that may improve crawling efficiency and discovery faster than many other technical changes. If the file is simply being refined to reduce crawl waste, the benefits may appear more gradually.
It is also important to stay realistic. Robots.txt SEO does not create ranking growth on its own. It helps search engines spend attention more effectively and reduces technical friction. That is valuable, but it works best alongside strong site structure, clean indexation signals, and useful content.
Conclusion
Robots.txt SEO matters because it helps control how crawlers interact with a website.
Used correctly, it supports crawl efficiency, reduces wasted attention on low-value sections, and strengthens the site’s technical clarity. Used carelessly, it can block important pages, create indexing confusion, and undermine broader SEO work.
The strategic takeaway is simple: use robots.txt to manage crawl priorities, not as a shortcut for every technical SEO problem. It is most effective when it aligns with the rest of the site’s technical system, including crawling and indexing rules, XML sitemaps, canonical signals, and internal linking.
For websites that want sustainable organic growth, that kind of disciplined technical control is far more valuable than a file that merely exists.